AI models collapse when trained on recursively generated data
AI models collapse when trained on recursively generated data
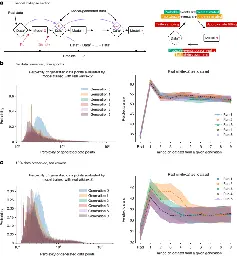
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
Of course they do, that's not really a shocking statement. I do like this research though, actually looking at how the underlying data distribution is forgotten.
So more or less AI inbreeding?
More like AI prion disease.
(There's also a process where people merge AI models together, and models are merges of merges with a largely unknown lineage, and in this space there's a growing inbreeding problem.)
lol best description of what's happening
hAIpsberg
AI kessler syndrome

So do i…

So basically the only way to have good "AI"
LLMsis for it to be a mechanical turk?
What if my robot was just a guy?
Not really AI if they can't learn from one another.
You mean LLMs aren't really AI???? Double
indiscriminate use of model-generated content
Indiscriminate is the key word in this paper. No one trains this way. Synthetic data and filtering out bad data are already very important steps for training and will continue to stay that way. With proper filtering and evaluation, models trained on synthetic data do better then the ones before.
This is not the end of ai, like so many wish it would be.
I don't think this is going to be the end of AI either, and the corpus of data before AI generated content became prevalent is also huge. So, I don't think there's really lack of training data. I personally think this is more interesting from the perspective of how these algorithms work in general. The fact that they end up collapsing when consuming their own content seems to indicate that the quality of content is fundamentally different from that generated by humans.
It's obvious enough that this will happen if you cycle one model's output through itself, but they looked at different types of models (LLMs, VAEs, and GMMs) and found the same collapse in all of them. I think that's a big finding.
 Recursively Generated Data
Recursively Generated Data Aggression to the Mean
Aggression to the MeanRampancy

Rampancy if instead of becoming hyper intelligent beyond moral constraints you instead got dementia
 Look mack, I should be going, my wife Dr. Jill Cortana has to use the email
Look mack, I should be going, my wife Dr. Jill Cortana has to use the email
 = The answer generated by the most sophisticated generative LLM's mankind will ever generate.
= The answer generated by the most sophisticated generative LLM's mankind will ever generate.That's what Inbred breeding does to A.I.