You can get the resulting PPL but that's only gonna get you a sanity check at best, an ideal world would have something like lmsys' chat arena and could compare unquantized vs quantized but that doesn't yet exist
So you don't have to click the link, here's the full text including links:
>Some of my favourite @huggingface models I've quantized in the last week (as always, original models are linked in my repo so you can check out any recent changes or documentation!): > >@shishirpatil_ gave us gorilla's openfunctions-v2, a great followup to their initial models: https://huggingface.co/bartowski/gorilla-openfunctions-v2-exl2 > >@fanqiwan released FuseLLM-VaRM, a fusion of 3 architectures and scales: https://huggingface.co/bartowski/FuseChat-7B-VaRM-exl2 > >@IBM used a new method called LAB (Large-scale Alignment for chatBots) for our first interesting 13B tune in awhile: https://huggingface.co/bartowski/labradorite-13b-exl2 > >@NeuralNovel released several, but I'm a sucker for DPO models, and this one uses their Neural-DPO dataset: https://huggingface.co/bartowski/Senzu-7B-v0.1-DPO-exl2 > >Locutusque, who has been making the Hercules dataset, released a preview of "Hyperion": https://huggingface.co/bartowski/hyperion-medium-preview-exl2 > >@AjinkyaBawase gave an update to his coding models with code-290k based on deepseek 6.7: https://huggingface.co/bartowski/Code-290k-6.7B-Instruct-exl2 > >@Weyaxi followed up on the success of Einstein v3 with, you guessed it, v4: https://huggingface.co/bartowski/Einstein-v4-7B-exl2 > >@WenhuChen with TIGER lab released StructLM in 3 sizes for structured knowledge grounding tasks: https://huggingface.co/bartowski/StructLM-7B-exl2 > >and that's just the highlights from this past week! If you'd like to see your model quantized and I haven't noticed it somehow, feel free to reach out :)
Interesting, hadn't heard of it before today, but guess I don't look at European car brands that often anyways
Ah I mean fair enough :) I don't keep up much with car brands and ownerships, but still TIL haha
Huh, didn't realize Volvo was primarily owned by a Chinese company, you got me there lol, genuinely always thought they were standalone and therefore a Swedish company
I don't understand the title, twitch isn't mentioned anywhere in the article is it??
Colour me intrigued. I want more manufactures that go against the norm. If they put out a generic slab with normal specs at an expected price, I won't be very interested, but if they do something cool I'm all for it
Except I just noticed the part where it's developed by Meizu so nevermind probably will be a generic Chinese phone
Stop making me want to buy more graphics cards...
Seriously though this is an impressive result, "beating" gpt3.5 is a huge milestone and I love that we're continuing the trend. Will need to try out a quant of this to see how it does in real world usage. Hope it gets added to the lmsys arena!
A multimodal, function calling powered LLM webui. - GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.

> PolyMind is a multimodal, function calling powered LLM webui. It's designed to be used with Mixtral 8x7B + TabbyAPI and offers a wide range of features including:
> Internet searching with DuckDuckGo and web scraping capabilities. > > Image generation using comfyui. > > Image input with sharegpt4v (Over llama.cpp's server)/moondream on CPU, OCR, and Yolo. > > Port scanning with nmap. > > Wolfram Alpha integration. > > A Python interpreter. > > RAG with semantic search for PDF and miscellaneous text files. > > Plugin system to easily add extra functions that are able to be called by the model. 90% of the web parts (HTML, JS, CSS, and Flask) are written entirely by Mixtral.
Nomic releases a 8192 Sequence Length Text Embedder that outperforms OpenAI text-embedding-ada-002 and text-embedding-v3-small.
Open source
Open data
Open training code
Fully reproducible and auditable
Pretty interesting stuff for embeddings, I'm going to try it for my RAG pipeline when I get a chance, I've not had as much success as I was hoping, maybe this english-focused one will help
If you go for it and need any help lemme know I've had good results with Linux and Nvidia lately :)
Btw I know this is old and you may have already figured out your hardware and setup, but p40s and p100s go for super cheap on eBay.
P40 is an amazing $/GB deal, only issue is the fp16 performance is abysmal so you'll want to run either full fp32 models or use llama.cpp which is able to cast up to that size
The p100 has less VRAM but really good fp16 performance which makes it ideal for exllamav2 usage. I picked up one of each recently, p40 was failed to deliver and p100 was delivered while I'm away, but once I have both on hand I'll probably post a comparison to my 3090 for interests sake
Also I run all my stuff on Linux (Ubuntu 22.04) with no issues
You shouldn't need nvlink, I'm wondering if it's something to do with AWQ since I know that exllamav2 and llama.cpp both support splitting in oobabooga
Yeah q2 logic is definitely a sore point, I'd highly recommend going with Mistral dolphin 2.6 DPO instead, the answers have been very high quality for a 7b model
But good info for anyone wanting to keep up to date on very low bit rate quants!
I don't have a lot of experience with either at this time, I've used them here and there for programming questions but usually I stick to 7b models because I use them for code completion and I only find that useful if it completes the code before I do lol
That said, I've had overall good answers from either whenever I've decided to pull them out, it feels like wizard coder should be better since it's so much newer but overall it hasn't been that different. Wish phind would release an update :(
Thanks to Charles for the conversion scripts, I've converted several of the new internLM2 models into Llama format. I've also made them into ExLlamaV2 while I was at it.
You can find them here:
https://huggingface.co/bartowski?search_models=internlm2
Note, the chat models seem to do something odd without outputting [UNUSED_TOKEN_145] in a way that seems equivalent to <|im_end|>, not sure why, but it works fine despite outputting that at the end.
I run my Nvidia stuff in containers to not have to deal with all the stupid shenanigans
The 3060 is a nice cheap one for running okay sized models, but if you can find a way to stretch for a 3090 or a 7900 XTX you'll be able to run these 33B models with decent quant levels
First few quants are up: https://huggingface.co/bartowski/WizardCoder-33B-V1.1-exl2
4.25 should fit nicely into 24gb (3090, 4090)
Smaller sizes still being created, 3.5, 3.0, and 2.4
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Based off of deepseek coder, the current SOTA 33B model, allegedly has gpt 3.5 levels of performance, will be excited to test once I've made exllamav2 quants and will try to update with my findings as a copilot model
I live in Ontario where we go down to -30C in the harshest conditions.
We have a heat pump and a furnace and they alternate based on efficiency
Somewhere around -5 to +5 C it switches from the heat pump to the furnace
I think you could get by a bit colder but it really loses out on efficiency vs burning gas unless you invest in a geothermal heat pump
Paper abstract: > Recent work demonstrates that, after being fine-tuned on a high-quality instruction dataset, the resulting model can obtain impressive capabilities to address a wide range of tasks. However, existing methods for instruction data generation often produce duplicate data and are not controllable enough on data quality. In this paper, we extend the generalization of instruction tuning by classifying the instruction data to 4 code-related tasks and propose a LLM-based Generator-Discriminator data process framework to generate diverse, high-quality instruction data from open source code. Hence, we introduce CodeOcean, a dataset comprising 20,000 instruction instances across 4 universal code-related tasks,which is aimed at augmenting the effectiveness of instruction tuning and improving the generalization ability of fine-tuned model. Subsequently, we present WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. This model is specifically designed for enhancing instruction tuning of Code Language Models (LLMs). Our experiments demonstrate that Wavecoder models outperform other open-source models in terms of generalization ability across different code-related tasks at the same level of fine-tuning scale. Moreover, Wavecoder exhibits high efficiency in previous code generation tasks. This paper thus offers a significant contribution to the field of instruction data generation and fine-tuning models, providing new insights and tools for enhancing performance in code-related tasks.
Seems relatively uncensored, willing to answer most questions
It's definitely a little odd.. I'm glad they did any kind of official release for 0.2, but yeah information is sorely lacking and would be nice to have more, especially with how revolutionary the previous one was.. is this incremental? Is it a huge change? Is it just more fine tuning? Did they start from scratch? We'll never know 🤷♂️
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

Available in instruct only currently:
https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
The only concern I had was my god is it a lot of faith to put in this random twitter, hope they never get hacked lol, but otherwise yes it's a wonderful idea, would be a good feature for huggingface to speed up downloads/uploads
Yeah this seems less focused on creativity, there's a lot of really good models out there tuned for story telling that will far exceed generalized SoTA models
Early speculation is that it's an MoE (mixture of experts) of 8 7b models, so maybe not earth shattering like their last release but highly intriguing, will update with more info as it comes out
At Microsoft, we’re expanding AI capabilities by training small language models to achieve the kind of enhanced reasoning and comprehension typically found only in much larger models.

Orca 2 released by Microsoft!
Full weights here:
https://huggingface.co/microsoft/Orca-2-7b
https://huggingface.co/microsoft/Orca-2-13b
My own exllamav2 quants here:
https://huggingface.co/bartowski/Orca-2-7b-exl2
https://huggingface.co/bartowski/Orca-2-13b-exl2
GGUF from TheBloke (links to GPTQ/AWQ inside it):
https://huggingface.co/TheBloke/Orca-2-7B-GGUF
https://huggingface.co/TheBloke/Orca-2-13B-GGUF
The situation at OpenAI is getting even more dicey.

<p>Announcing Llama-rephraser: 13B models reaching GPT-4 performance in major benchmarks (MMLU/GSK-8K/HumanEval)! To ensure result validity, we followed Open...</p>
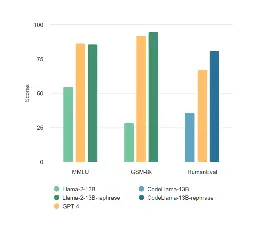
LMSYS examines how improper data decontamination can lead to artificially inflated scores
H200 is up to 1.9x faster than H100. This performance is enabled by H200's larger, faster HBM3e memory.
https://nvidianews.nvidia.com/news/nvidia-supercharges-hopper-the-worlds-leading-ai-computing-platform
Web UI for ExLlamaV2. Contribute to turboderp/exui development by creating an account on GitHub.

The creator of ExLlamaV2 (turboderp) has released a lightweight web UI for running exllamav2, it's quite nice! Missing some stuff from text-generation-webui, but makes up for it by being very streamlined and clean
I've made a docker image for it for anyone who may want to try it out, GitHub repo here:
https://github.com/noneabove1182/exui-docker
And for finding models to run with exllamav2 I've been uploading several here:
https://huggingface.co/bartowski
Enjoy!
Phind is now using a V7 of their model for their own platform, as they have found that people overall prefer that output vs GPT4. This is extremely impressive because it's not just a random benchmark that can be gamed, but instead crowd sourced opinion on real tasks
The one place everything still lags behind GPT4 is question comprehension, but this is a huge accomplishment
Blog post: https://www.phind.com/blog/phind-model-beats-gpt4-fast
note: they've only open released V2 of their model, hopefully they release newer versions soon.. would love to play with them outside their sandbox
The way that this sampler works is: Every possible token has a probability percentage attached to it that we will be measuring for consideration. The base min p value represents the starting requi...
![Min P sampler implementation [alternative to Top P/Top K] by kalomaze · Pull Request #3841 · ggerganov/llama.cpp](https://sh.itjust.works/pictrs/image/4dfdf716-636a-4de3-abb7-88b070ba673b.png?format=webp&thumbnail=256)
Very interesting new sampler, does a better drop at filtering out extremely unlikely tokens when the most likely tokens are less confident, from the results it seems to pretty reliably improve quality with no noticeable downside
Releasing a new version of the RedPajama dataset, with 30 trillion filtered and deduplicated tokens (100+ trillions raw) from 84 CommonCrawl dumps covering 5 languages, along with 40+ pre-computed data quality annotations that can be used for further filtering and weighting.

30T tokens, 20.5T in English, allegedly high quality, can't wait to see people start putting it to use!
Related github: https://github.com/togethercomputer/RedPajama-Data

Finally got a nice script going that automates most of the process. Uploads will all be same format, with each bit per weight going into its own branch.
the first two I did don't have great READMEs but the rest will look like this one: https://huggingface.co/bartowski/Mistral-7B-claude-chat-exl2
Also taking recommendations on anything you want to see included in readme or quant levels
For anyone who happens to be using my docker images or Dockerfiles for their text-gen-webui, it all started breaking this week when Oobabooga's work was updated to support 12.1
As such, I have updated my docker images and fixed a bunch of issues in the build process. Also been awhile since I posted it here.
You can find all the details here:
https://github.com/noneabove1182/text-generation-webui-docker
It requires driver version 535.113.01
Happy LLMing!
From the tweet (minus pictures):
Language models are bad a basic math.
GPT-4 has right around 0% accuracy rate on 5 digit multiplication.
Most open models can't even add. Why is that?
There are a few reasons why numbers are hard. The main one is Tokenization. When training a tokenizer from scratch, you take a large corpus of text and find the minimal byte-pair encoding for a chosen vocabulary size.
This means, however, that numbers will almost certainly not have unique token representations. "21" could be a single token, or ["2", "1"]. 143 could be ["143"] or ["14", "3"] or any other combination.
A potential fix here would be to force single digit tokenization. The state of the art for the last few years is to inject a space between every digit when creating the tokenizer and when running the model. This means 143 would always be tokenized as ["1", "4", "3"].
This helps boost performance, but wastes tokens while not fully fixing the problem.
A cool fix might be xVal! This work by The Polymathic AI Collaboration suggests a generic [NUM] token which is then scaled by the actual value of the number!
If you look at the red lines in the image above, you can get an intuition for how that might work.
It doesn't capture a huge range or high fidelity (e.g., 7.4449 vs 7.4448) but they showcase some pretty convincing results on sequence prediction problems that are primarily numeric.
For example, they want to train a sequence model on GPS conditioned temperature forecasting
They found a ~70x improvement over standard vanilla baselines and a 2x improvement over really strong baselines.
One cool side effect is that deep neural networks might be really good at regression problems using this encoding scheme!