It's no reddit in terms of quantity but honesty I've had higher quality topics and discussions here than there. Lemmy/kbin might not have taken off in the mainstream to offer a variety of subjects but when it comes to tech and software I think it's covered well enough and people are generally nicer about it. The main problem is lack of (remotely) good seach function, I dont think the threads are getting indexed by google and the on-site search is atrocious.
I don't know of any discord programming communities, I wish forums were still a thing but the only live one I know of is the jellyfin one after they moved from reddit. Other than that it's here or the various subreddits
I'm hooked all over again, can't wait to get to new content
Thanks for the suggestion! I'm struggling a bit to incorporate that command into podman compose though, I'm reading through this issue and I'm a bit lost.
Do I just add this to sonarr section in my yaml? I tried it and it doesn't seem to have done much
x-podman:
keep-id:uid=1000
Should I try and switch everything to podman kube play as some user there recommended maybe?
I've been migrating to linux recently and next headache on the list are my starr apps (sonarr, radarr, etc). On windows I just had them installed as background services but I wanted to give (rootless) podman a try on linux since everyone kept recommending it and saying how much better the experience is than on windows.
Anyway, I've set everything up and some of the services work, but specifically sonarr and radarr can't write to the main media folder with the error: Folder '/data/media/tv/' is not writable by user 'abc'
So, first of all, I didn't make user 'abc', it is some internal docker/podman/starr user allegedly and it's supposed to be mapped to my real user, which I did by providing the PUID=1000, PGID=1000 env variables.
Second, I tried to give read and write permissions to everyone for the placeholder folders but it didn't change anything. I don't think this is the issue since other services like the one for sabnzbd or jellyfin had no problems using folders I created.
Googling for the issue brought up some topics about NFS shares but I don't know anything about this - this is not a NAS or even some external drive, it's just podman installed on fedora.
Any help is appreciated, here's a pastebin of my compose file if it's relevant https://pastebin.com/uX9Saqvj
From what I read on their homepage, RPM Fusion just provides non-free software that Fedora/RH don't usually want to ship themselves, it's just precompiled RPMs for all available Fedora versions. Sounds to me like it should be the same, my currently installed nvidia driver version is 555.58.02 but I have no idea if that correlates to the version of 'nvidia software' app. Ugh every issue is just a pandora box of 10 other problems jumping out and strangling you
edit: Seems to have something to do with wayland/xorg? https://old.reddit.com/r/Fedora/comments/zxvrxk/nvidia_x_server_settings/ I have no idea what are the implications of this though
First of all, thanks for the suggestion! I am a bit confused though because my NVIDIA settings doesn't have nearly as many options as that one:
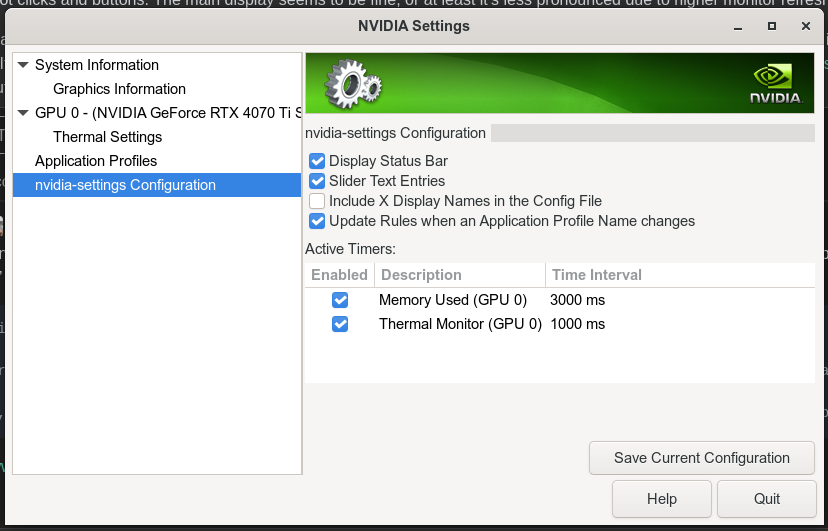
Do I have something incorrectly installed? I followed the instructions from the linked resource to install the rpm fusion nvidia drivers since they aren't available on fedora 40 on the store even with the 3rd party repositories enabled
I could swear that my mouse is lagging on my second monitor but I don't how how to actually "prove" it, if there's even a way. I am dual booting windows with fedora workstation gnome and there is a noticeable sluggishness to my mouse control whenever I switch back and forth, but only on the secondary monitor. It is slight but it's messing with my muscle memory and constantly making me overshoot clicks and buttons. The main display seems to be fine, or at least it's less pronounced due to higher monitor refresh rate.
Is there any way I can measure it objectively and find the root cause? A diagnostic tool or an app that could test if something is wrong? It's a recent fedora installation and I've gone through all the nvidia driver and media setup steps at this fedora post-install guide but honestly I don't even know if this is a fedora, gnome, driver or wayland issue (or something else completely)
Doesn't that imply you still have to open up your phone to temporarily share to your pc whenever you need it?
If I do all that then my feed is going to be even emptier than it is now
Similar experience here. I have a nicely curated list of people I follow on twitter, they often retweet other users that are similar and I have a nice feed of good content that slowly grows without ever running into toxic assholes. On mastodon I couldn't get anywhere close to that no matter how much I tried.
I have a mastodon account, I still check it occasionally and I've tried making it work a year ago, being active on it and following either people or hashtags. I also tried other networks like bsky and cara, or mastodon through kbin integration. None of them really worked out.
I didn't have an issue with the technical side as much as with the community and its mentality. They all have this persecution complex where everyone is out to get them and destroy their way of living. They simultaneously claim it's better and more morally superior than twitter while also responding to any questions or feedback with "if you don't like it GTFO". Most of the posts I've seen on mastodon seemed masturbatory and/or talking about other social networks and why are they bad than why is mastodon actually good. In many ways it was more toxic and negative than my carefully curated twitter feed. There's also as much doom and gloom as on twitter, if not more, when it comes to politics (or at least, it's harder to hide it).
The content in general was bad and boring but I don't know if this is because of the type of people that are on it or just because the lack of algorithm means I will see any random person's ramblings next to the biggest breaking news that I'm actually interested in. There is a lack of innovation in this area and it makes discoverability and content curation terrible, I don't need an algorithm to read my mind but at the very least I wish it could separate trash from actual popular topics.
I found some interesting niches when it comes to FOSS developers and tech but I found next to no actual game devs, artists or content creators on it and even the usual "copy content from twitter" bots were unreliable and uncommon.
TL;DR Mastodon seems very very niche and is not currently viable as a general replacement for other social networks, and IMHO due to the community culture there it's never going to grow into anything else either.
One more reason why Git-Fork is the GOAT - it does have separate subject and description fields. Don't lump all GUI tools in together and generalize
I was aware of some people trying to get it working on wine but last I checked it wasn't really going anywhere, there were some big blockers there, and I didn't know the developers were interested in it at all.
Fork and VS are probably the top 2 pieces of software I'm missing to fully migrate to linux so I'd be very happy if they developed an official port that works as well as it does on win.
although they are experimenting with it)
Do you have a source for this maybe? This is very exciting news but I don't wanna get my hopes up if it's not true
I guess I just don't trust myself (or the system) to keep stuff organized unless I do it meticulously myself from the start in a neat hierarchy. I'll try to use search more often since it does seem fast and sleek and see how it works out. The only annoying part about it is that it always defaults to my primary display for search even if im focused on the second monitor
Do you know of a good guide on how to use search better, like can I narrow so it only shows files and folders, or maybe match to a regex like *.js? it doesn't really find specific files when i search for them, is it supposed to work with other mounted drives as well?
gnome-shell-pano looks great but is it abandoned? It says my current (newest i assume) gnome shell version is not supported by the extension. Does it open the paste window where your mouse focus is (and on the correct monitor if you have more than one)? CH always opens it on the main display even if i'm focused on the secondary, its horrible...
I found I already have an installed gnome extension 'hot edge' that is supposed to do dock opening when hitting the edge, although i do have issues with it sometimes not triggering, it seems very focus sensitive but it's definitely better than nothing.
It's definitely an interesting experience and I don't want it to replicate windows, but i guess i need to come to terms with some design decisions that will feel unnatural after using windows for almost 20 years now.
VScodium
I tried this but it seems that VSCodium is missing many of the extensions that are available on VSCode, it has something to do with them using different extension registries?
In any case thanks for the advice but they don't seem to be completely equal in terms of features
It's been a while since I used ubuntu and popOS was only for a few days so maybe I was just mistaken, I remember it being somewhat comparable to a classic desktop at the time but it could have been that cosmic shell thing. And tbh until so far I thought cinnamon is gnome so it seems like I was just outright wrong about that one, thanks for clarifying
I'm definitely willing to try bazzite's gnome3 for a while, i just wasn't sure what's the default anymore and if it's bazzite doing something out of the norm or if the ubuntu based distros did.
tl;dr KB+M and no touchpad here so that might have something to do with it, I prefer more compact and colorful UIs, and different behavior between LMB and RMB.
I'm not a big fan of the Nautilus file manager, all the rows seem too big and too padded. There is no compact mode and from what I've read changing the default file manager is a big no-no in linux since the OS depends on it (and I did try to install Dolphin just to compare but the theme was unusable with bazzite). I can't even pin other drives to the left navigation pane, only folders? The monochromatic theme is neat but just makes it more difficult to tell things apart, gimme some color please yellow folders.
I know the no desktop decision is "since they always get cluttered anyways", but making me use a folder instead will just force me to use a cluttered folder instead, or more likely keep stuff in Downloads. At least with the desktop I can visually arrange it.
I miss the taskbar for switching apps. I do agree pressing the win/command button is neat and practical but sometimes I just want to switch to a different app on my second monitor using mouse only (or see notifications from it) without moving my keyboard hand.
Then it's the small things - I did install the clipboard manager gnome extension (because copyq doesn't work with wayland apparently) but it always opens it in a corner, not on my mouse location.
Systray - left and right mouse buttons do the same thing and doubleclicking does nothing? For example to open the steam window from it I always have to click it, go down to library and click again, this is the default behavior of RMB in other OSes and here it's the only behavior.
Minimizing something and then immediately alt-tabbing doesn't bring that window back up, some focus issue? Two monitors issue? Dunno but annoying.
Is gnome 3 the one without a desktop? The only thing I can figure out with gnome-shell --version is that bazzite uses 46.4
There is a KDE variant of bazzite I might try but I dont know what can of worms is that going to open
Dumb title but I didn't know how else to put this into words, bear with me for a sec - I am not just looking for the definition.
Years ago I tried Ubuntu which used GNOME and assumed that its desktop layout was "the default" GNOME. I later tried PopOS which also uses it and it was the same, and when eventually I installed Mint I saw that it's still fundamentally the same with some slight tweaks or different tools.
Well, few days ago I installed Bazzite (Fedora) which is also GNOME. It doesn't look anything like anything I've seen before, either in terms of mindset or technical layout. I've gone from an admittedly old-fashioned, but efficient and reliable!, layout and workflow to something that reminds me more of an apple product - its stylish, minimalist yet inefficient and utterly frustrating to get anything done with because of how opinionated it is.
When searching for common problems I often found comments saying stuff like "but try it out! it's in the spirit of gnome, it takes a while to get used to it but the philosophy is valid" and frankly I don't understand anymore what exactly gnome is and what are its design principles, if there even are any and every distro just does whatever the f it wants and call it "a gnome experience".
How will manually retyping git pull or checkout 30+ times a day, or using the terminal log instead of a nice GUI with VSCode integration, teach me to solve other complicated issues? I just don't really see the benefit of struggling for most of the time for something that might or might not happen later
When you need more advanced stuff then GUIs tend to become more of a sticking point I find
What's stopping you just opening the terminal in those rare cases? For 99% of my daily needs I'm good with a good GUI
I need to remote desktop connect to a windows PC on a local network. This works flawlessly when done from my windows PC but I'm having issues on Linux Mint.
I'm using Remmina since it was the most common answer to a linux RDP client. I imported the RDP file from windows but I also created a connection with manually filled info.
First issue is that linux can't connect to the machine by its name - on windows ping MYPC-321 works, on linux mint it throws an error. However, ping MYPC-321.local does work, but if I try to use that as the address in Remmina, it fails again. Is there a way to connect using just name since I dont want to have to recheck the IP address every day?
But let's say this is for now resolved if I just use the local IP address. The second, main problem, is authentication. No matter what I put into the username and domain fields of Remmina's authentication GUI, it always instantly fails and Remmina reloads the screen without giving me any error. The credentials are the same as when connecting from the windows PC (although I dont have to specify the domain there) so I have no idea what could be the problem here.
Is there something else I'm missing, something fundamentally different about how this works on linux? I wasn't expecting for such a simple and straightforward thing to instantly cause issues.
cross-posted from: https://programming.dev/post/18636248
> I've always approached learning Linux by just diving into it and bashing my head against problems as they come until I either solve them or give up, the latter being the more common outcome. > > I wouldn't take this approach with other pieces of software though - I'd read guides, best practices, have someone recommend me good utility tools or extensions to install, which shortcuts to use or what kind of file hierarchy to use, etc. > For example, for python I'd always recommend the "Automate the boring stuff with Python", I remember learning most Java with that "Head first Java" book back in the days, c# has really good official guides for all concepts, libraries, patterns, etc. > > So... lemme try that with Linux then! Are there any good resources, youtube videos, bloggers or any content creators, books that go explain everything important about linux to get it running in an optimal and efficient way that are fun and interesting to read? From things like how the file hierarchy works, what is /etc, how to install new programs with proper permissions, when to use sudo, what is a flatpak and why use it over something else, how to backup your system so you can easily reconstruct your setup in case you need to do an OS refresh, etc? All those things that people take for granted but are actually a huge obstacle course + minefield for beginners? > > And more importantly, that it's up to date with actually good advice?
I've always approached learning Linux by just diving into it and bashing my head against problems as they come until I either solve them or give up, the latter being the more common outcome.
I wouldn't take this approach with other pieces of software though - I'd read guides, best practices, have someone recommend me good utility tools or extensions to install, which shortcuts to use or what kind of file hierarchy to use, etc. For example, for python I'd always recommend the "Automate the boring stuff with Python", I remember learning most Java with that "Head first Java" book back in the days, c# has really good official guides for all concepts, libraries, patterns, etc.
So... lemme try that with Linux then! Are there any good resources, youtube videos, bloggers or any content creators, books that go explain everything important about linux to get it running in an optimal and efficient way that are fun and interesting to read? From things like how the file hierarchy works, what is /etc, how to install new programs with proper permissions, when to use sudo, what is a flatpak and why use it over something else, how to backup your system so you can easily reconstruct your setup in case you need to do an OS refresh, etc? All those things that people take for granted but are actually a huge obstacle course + minefield for beginners?
And more importantly, that it's up to date with actually good advice?
I understand the basic principle but I have trouble determining what is the hard line separating responsibilities of a Repository or a Service. I'm mostly thinking in terms of c# .NET in the following example but I think the design pattern is kinda universal.
Let's say I have tables "Movie" and "Genre". A movie might have multiple genres associated with it. I have a MovieController with the usual CRUD operations. The controller talks to a MovieService and calls the CreateMovie method for example.
The MovieService should do the basic business checks like verifying that the movie doesn't already exist in the database before creating, if all the mandatory fields are properly filled in and create it with the given Genres associated to it. The Repository should provide access to the database to the service.
It all sounds simple so far, but I am not sure about the following:
-
which layer should be responsible for column filtering? if my Dto return object only returns 3 out of 10 Movie fields, should the mapping into the return Dto be done on the repository or service layer?
-
if I need to create a new Genre entity while creating a new movie, and I want it to all happen in a single transaction, how do I do that if I have to go through MovieRepository and GenreRepository instead of doing it in the MovieService in which i don't have direct access to the dbcontext (and therefore can't make a transaction)?
-
let's say I want to filter entries specifically to the currently logged in user (every user makes his own movie and genre lists) - should I filter by user ID in the MovieService or should I implement this condition in the repository itself?
-
is the EF DbContext a repository already and maybe i shouldn't make wrappers around it in the first place?
Any help is appreciated. I know I can get it working one way or another but I'd like to improve my understanding of modern coding practices and use these patterns properly and efficiently rather than feeling like I'm just creating arbitrary abstraction layers for no purpose.
Alternatively if you can point me to a good open source projects that's easy to read and has examples of a complex app with these layers that are well organized, I can take a look at it too.
Let's say I am making an app that has table Category and table User. Each user has their own set of categories they created for themselves. Category has its own Id identity that is auto-incremented in an sqlite db.
Now I was thinking, since this is the ID that users will be seeing in their url when editing a category for example, shouldn't it be an ID specific only to them? If the user makes 5 categories they should see IDs from 1 to 5, not start with 14223 or whichever was the next internal ID in the database. After all when querying the data I will only be showing them their own categories so I will always be filtering on UserId anyway.
So let's say I add a new column called "UserSpecificCategoryId" or something like that - how do I make sure it is autogenerated in a safe way and stays unique per user? Do I have to do it manually in the code (which sounds annoying), use some sort of db trigger (we hate triggers, right?) or is this something I shouldn't even be bothering with in the first place?
Let's say I have a method that I want to make generic, and so far it had a big switch case of types.
For an simplified example,
csharp switch (field.GetType()) { case Type.Int: Method((int)x)... case Type.NullInt: Method((int?)x)... case Type.Long: Method((long)x)...
I'd like to be able to just call my GenericMethod<T>(field) instead and I'm wondering if this is possible and how would I go around doing it.
```csharp GenericMethod(field)
public void GenericMethod<T>(T field) ```
Can I use reflection to get a type and the pass it into the generic method somehow, is it possible to transform Type into <T>?
Can I have a method on the field object that will somehow give me a <T> type for use in my generic method?
Sorry for a confusing question, I'm not really sure how to phrase it correctly, but basically I want to get rid of switch cases and lots of manual coding when all I need is just the type (but that type can't be passed as generic from parent class)
To clarify, I mean writing scripts that generate or modify classes for you instead of manually writing them every time, for example if you want to replace reflection with a ton of verbose repetitive code for performance reasons I guess?
My only experience with this is just plain old manual txt generation with something like python, and maintaining legacy t4/tt VS files but those are kind of a nightmare.
What's a good modern way of accomplishing this, have there been any improvements in this area?
I don't have access to my router and my ISP charges for port forwarding (I think they might have a CGNAT setup?).
I'm trying to work around that since I want to start hosting some apps and game servers from my PC. I'm seeing a lot of talk about tailscale as a possible solution to this but honestly I'm a bit confused with all the options and whether this is actually the proper tool for the job.
Assuming it is, do I go the route of setting up a "tailscale funnel" or a "subnet"? Will other people have to install tailscale too if they want to join my servers? People also mention Netmaker or Cloudflared Tunnel, although it also seems like cloudflare doesn't want their tunnels used for game and media traffic?
The more expensive option I guess would be just paying for protonvp premium since it offers port forwarding in that case, but I'm not sure about performance and whether it's worth it, at that point I might just rent a server instead.
Hoping you folks at self-hosted have more ideas on how can I, well... self host instead of throwing money at the problem.
cross-posted from: https://programming.dev/post/6513133
> Short explanation of the title: imagine you have a legacy mudball codebase in which most service methods are usually querying the database (through EF), modifying some data and then saving it in at the end of the method. > > This code is hard to debug, impossible to write unit tests for and generally performs badly because developers often make unoptimized or redundant db hits in these methods. > > What I've started doing is to often make all the data loads before the method call, put it in a generic cache class (it's mostly dictionaries internally), and then use that as a parameter or a member variable for the method - everything in the method then gets or saves the data to that cache, its not allowed to do db hits on its own anymore. > > I can now also unit test this code as long as I manually fill the cache with test data beforehand. I just need to make sure that i actually preload everything in advance (which is not always possible) so I have it ready when I need it in the method. > > Is this good practice? Is there a name for it, whether it's a pattern or an anti-pattern? I'm tempted to say that this is just a janky repository pattern but it seems different since it's more about how you time and cache data loads for that method individually, rather than overall implementation of data access across the app. > > In either case, I'd like to learn either how to improve it, or how to replace it.
Short explanation of the title: imagine you have a legacy mudball codebase in which most service methods are usually querying the database (through EF), modifying some data and then saving it in at the end of the method.
This code is hard to debug, impossible to write unit tests for and generally performs badly because developers often make unoptimized or redundant db hits in these methods.
What I've started doing is to often make all the data loads before the method call, put it in a generic cache class (it's mostly dictionaries internally), and then use that as a parameter or a member variable for the method - everything in the method then gets or saves the data to that cache, its not allowed to do db hits on its own anymore.
I can now also unit test this code as long as I manually fill the cache with test data beforehand. I just need to make sure that i actually preload everything in advance (which is not always possible) so I have it ready when I need it in the method.
Is this good practice? Is there a name for it, whether it's a pattern or an anti-pattern? I'm tempted to say that this is just a janky repository pattern but it seems different since it's more about how you time and cache data loads for that method individually, rather than overall implementation of data access across the app.
In either case, I'd like to learn either how to improve it, or how to replace it.
Was just wondering what's popular nowadays, maybe I find something new and better - what kind of tools are you using to access and manage databases?
I'm personally using Dbeaver a lot but honestly it feels increasingly more buggy and unreliable as time passes, every installation and update has had (unique) issues so far and there's little support. However the ease of use and some powerful, convenient, utilities in it make it preferable to others.
It is a common sentiment that managing dependencies is always a big issue in software development and the reason why so many apps come pre-bundled with all the requirements so it reliably works on every machine.
However, I don't actually understand why is that an issue and why people generally bash npm and the way it's done there. Isn't it the simplest and most practical solution to a problem - you have a file which defines which other libraries you need, which version, and then with one command you can install them and run the program?
Furthermore, those libraries and their specific versions can be stored elsewhere and shared across all apps on a system so you can easily reuse them instead of having to redownload for each program individually.
I must be missing something since if it were that easy, people would have solved it years ago and agreed on a standardized best way, so I'm wondering what is the actual issue and a cause of so many headaches.
I see this often with both new and old developers, they have one way of doing a thing and when presented with a new problem they will fall back to what they are used to even if it's not the optimal solution. It will probably work if you bruteforce it into your usual patterns but sometimes, a different approach is much easier to implement and maintain as long as you are willing to learn it, and more importantly - know it exists in the first place.
On a less abstract level, I guess my question is - how would I go around learning about different design patterns and approaches to problem solving if I don't know about their existence in the first place? Is it just a matter of proactive learning and I should know all of them in advance, as well as their uses?
Let's for example say I need to create a system for inserting a large amount of data from files into the db, or you need to create some service with many scheduled tasks, or an user authentication system. Before you sit down and start developing those the way you usually do, what kind of steps could you take to learn a potentially better way of doing it?