The Irony of 'You Wouldn't Download a Car' Making a Comeback in AI Debates
The Irony of 'You Wouldn't Download a Car' Making a Comeback in AI Debates
Those claiming AI training on copyrighted works is "theft" misunderstand key aspects of copyright law and AI technology. Copyright protects specific expressions of ideas, not the ideas themselves. When AI systems ingest copyrighted works, they're extracting general patterns and concepts - the "Bob Dylan-ness" or "Hemingway-ness" - not copying specific text or images.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages. The AI discards the original text, keeping only abstract representations in "vector space". When generating new content, the AI isn't recreating copyrighted works, but producing new expressions inspired by the concepts it's learned.
This is fundamentally different from copying a book or song. It's more like the long-standing artistic tradition of being influenced by others' work. The law has always recognized that ideas themselves can't be owned - only particular expressions of them.
Moreover, there's precedent for this kind of use being considered "transformative" and thus fair use. The Google Books project, which scanned millions of books to create a searchable index, was ruled legal despite protests from authors and publishers. AI training is arguably even more transformative.
While it's understandable that creators feel uneasy about this new technology, labeling it "theft" is both legally and technically inaccurate. We may need new ways to support and compensate creators in the AI age, but that doesn't make the current use of copyrighted works for AI training illegal or unethical.
For those interested, this argument is nicely laid out by Damien Riehl in FLOSS Weekly episode 744. https://twit.tv/shows/floss-weekly/episodes/744
You're viewing a single thread.
This process is akin to how humans learn by reading widely and absorbing styles and techniques, rather than memorizing and reproducing exact passages.
Like fuck it is. An LLM "learns" by memorization and by breaking down training data into their component tokens, then calculating the weight between these tokens. This allows it to produce an output that resembles (but may or may not perfectly replicate) its training dataset, but produces no actual understanding or meaning--in other words, there's no actual intelligence, just really, really fancy fuzzy math.
Meanwhile, a human learns by memorizing training data, but also by parsing the underlying meaning and breaking it down into the underlying concepts, and then by applying and testing those concepts, and mastering them through practice and repetition. Where an LLM would learn "2+2 = 4" by ingesting tens or hundreds of thousands of instances of the string "2+2 = 4" and calculating a strong relationship between the tokens "2+2," "=," and "4," a human child would learn 2+2 = 4 by being given two apple slices, putting them down to another pair of apple slices, and counting the total number of apple slices to see that they now have 4 slices. (And then being given a treat of delicious apple slices.)
Similarly, a human learns to draw by starting with basic shapes, then moving on to anatomy, studying light and shadow, shading, and color theory, all the while applying each new concept to their work, and developing muscle memory to allow them to more easily draw the lines and shapes that they combine to form a whole picture. A human may learn off other peoples' drawings during the process, but at most they may process a few thousand images. Meanwhile, an LLM learns to "draw" by ingesting millions of images--without obtaining the permission of the person or organization that created those images--and then breaking those images down to their component tokens, and calculating weights between those tokens. There's about as much similarity between how an LLM "learns" compared to human learning as there is between my cat and my refrigerator.
And YET FUCKING AGAIN, here's the fucking Google Books argument. To repeat: Google Books used a minimal portion of the copyrighted works, and was not building a service to compete with book publishers. Generative AI is using the ENTIRE COPYRIGHTED WORK for its training set, and is building a service TO DIRECTLY COMPETE WITH THE ORGANIZATIONS WHOSE WORKS THEY ARE USING. They have zero fucking relevance to one another as far as claims of fair use. I am sick and fucking tired of hearing about Google Books.
EDIT: I want to make another point: I've commissioned artists for work multiple times, featuring characters that I designed myself. And pretty much every time I have, the art they make for me comes with multiple restrictions: for example, they grant me a license to post it on my own art gallery, and they grant me permission to use portions of the art for non-commercial uses (e.g. cropping a portion out to use as a profile pic or avatar). But they all explicitly forbid me from using the work I commissioned for commercial purposes--in other words, I cannot slap the art I commissioned on a T-shirt and sell it at a convention, or make a mug out of it. If I did so, that artist would be well within their rights to sue the crap out of me, and artists charge several times as much to grant a license for commercial use.
In other words, there is already well-established precedent that even if something is publicly available on the Internet and free to download, there are acceptable and unacceptable use cases, and it's broadly accepted that using other peoples' work for commercial use without compensating them is not permitted, even if I directly paid someone to create that work myself.
But they all explicitly forbid me from using the work I commissioned for commercial purposes
I fear the courts will side with the tech companies on this as regardless of how illegal or immoral a certain act is, if you do it on a large enough scale it becomes "okay" again in the eyes of the system. Genocide, large scale fraud, negligent financial actions, pollution/poisoning, etc. You dump toxic chemicals into one person's cup and you get the book thrown at you. You dump toxic chemicals into an entire city's water supply and you pay a paltry fine that is never enough to seriously damage the company because that's bad for the economy.
I recently visited a museum and i really loved it. Getting up close to an image and seeing none of the fuzziness, no AI "shimmer" on photos and every stroke made sense (as in you could see that an arm moved a brush and you could see the path it took etc.). Hands made sense. And while tryptichons were not exactly precise when it comes to the anatomy of humans, no humans had anything smeared etc.
If you put a gazillion monkeys on a typewriter they can write Shakespeare.
If you train one ai for a ton of epochs it can write Shakespeare.
All pure mathematical coincidence.
It was the best of times, it was the BLURST OF TIMES! Stupid monkey!
If you put a gazillion monkeys on a typewriter they can write Shakespeare.
This is a mathematical curiosity borne out of pure randomness. An LLM trained on a dataset to generate similar content is quite the opposite of randomness.
Like fuck it is. An LLM "learns" by memorization and by breaking down training data into their component tokens, then calculating the weight between these tokens.
But this is, at a very basic fundamental level, how biological brains learn. It's not the whole story, but it is a part of it.
there's no actual intelligence, just really, really fancy fuzzy math.
You mean sapience or consciousness. Or you could say "human-level intelligence". But LLM's by definition have real "actual" intelligence, just not a lot of it.
Edit for the lowest common denominator: I'm suggesting a more accurate way of phrasing the sentence, such as "there's no actual sapience" or "there's no actual consciousness". /end-edit
an LLM would learn "2+2 = 4" by ingesting tens or hundreds of thousands of instances of the string "2+2 = 4" and calculating a strong relationship between the tokens "2+2," "=," and "4,"
This isn't true. At all. There are math specific benchmarks made by experts to specifically test the problem solving and domain specific capabilities of LLM's. And you can be sure they aren't "what's 2 + 2?"
I'm not here to make any claims about the ethics or legality of the training. All I'm commenting on is the science behind LLM's.
Get a load of this maroon, they think LLMs are actually sapient! Thanks, I needed that laugh.
Get a load of this maroon, they think LLMs are actually sapient!
I guess reading comprehension is as bad here as it's ever been on the internet.
Fine, you win, I misunderstood. I still disagree with your actual point, however. To me, Intelligence implies the ability to learn in real-time, to adapt to changes in circumstance, and for self-improvement. Once an LLM is trained, it is static and unchanging until you re-train it with new data and update the model. Even if you strip out the sapience/consciousness-related stuff like the ability to think critically about a scenario, proactively make decisions, etc., an LLM is only capable of regurgitating facts and responding to its immediate input. By design, any "learning" it can do is forgotten the instant the session ends.
Fine, you win, I misunderstood.
It's not a competition, but I genuinely respect you for saying you misunderstood.
Once an LLM is trained, it is static and unchanging until you re-train it with new data and update the model.
Absolutely! I honestly think this is the main thing (or at least one of the main things) that prevent human-level intelligence or even sentience in LLM's.
Think about how our minds work. From the moment we're born (really, it's way before that) our brains are bombarded with input and feedback from every sense. It takes a person many months of that to start recognizing things. That's also why babies sleep so much, their brains are kinda "training" and growing fast. Organizing all the data into memories.
Side bar: this is actually what dreams are. Dreams are emotions, thoughts, ideas, or whatever concept a neuron or group of neurons are associated with getting triggered. When we dream it's our brain taking the days inputs and building new connections. The neural connections in our brains are very much like weights and feed-forward process of neural activation is near identical to how artificial neural networks function. They aren't called "artificial neural networks" for no reason.
Here's a useful graphic that shows things that make up "intelligence"
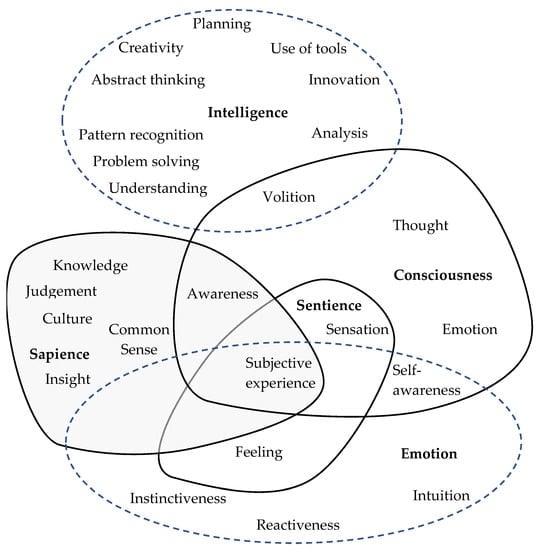
A very basic definition of intelligence is "the ability to solve problems or make decisions".
I think the term is just often misused in common parlance so often that people start applying in a scientific setting incorrectly. Kinda how people used to call an entire computer the CPU, which like the word intelligence everyone understands what's being said, but it's factually wrong.
Same thing today when people say "I bought a new GPU" when they should say "I bought a new video card" as the GPU is just a component.