
Fuck, that sounds too amazing to not try. Thanks for the idea! I'll try it the next Sunday, as I'm planning pork knuckles for lunch. (I'd try it today but I'm preparing Zebu hump so it doesn't combo that well.)
That reinforces what you said about being very likely in the autism spectrum - when I say "most people use implicatures all the time", the exceptions are typically people in the spectrum. Some can detect implicatures through analysis, and in some cases they have previous knowledge of a specific implicature so they can handle that one; but to constantly analyse what you hear, read, say and write is laborious and emotionally displeasing, it fits really well what you said in the OP.
(Interestingly that "all the time" that I used has the same implicature as the "all the millionaires" from your example - epistemically, the "all" doesn't convey "the complete set without exceptions" in either, but rather "a noteworthy large proportion of the set". "Boo millionaires" is also a good interpretation but it's about the attitude of the speaker, not the truth/falseness of the statement.)
This conversation gave me an idea - I'll encourage my mum (who's most likely in the autism spectrum) to give ChatGPT a try. Just to see her opinion about it.
I’m sure a linguist could dive way more into depth, but “not English words” is the equivalent of “not a true Scotsman”.
Pretty much. Once speakers start using the word, and expecting others to understand it, it's already part of the lexicon of that language. Specially if you see signs of phonetic adaptation, like /ø/ becoming /u:/ in a language with no /ø/ (see: "lieu") - and yet it's exactly why people complain about those words.
And this sort of complain isn't even new. Nor the backslash agianst it, as Catullus 84 shows for Latin and Greek.
No problem - I've seen worse. I've done worse.
(I'm fine, thanks! I hope you're doing well too.)
I think that the key here are implicatures - things that implied or suggested without being explicitly said, often relying on context to tell apart. It's situations like someone telling another person "it's cold out there", that in the context might be interpreted as "we're going out so I suggest you to wear warm clothes" or "please close the window for me".
LLMs model well the grammatical layer of a language, and struggle with the semantic layer (superficial meaning), but they don't even try to model the pragmatic layer (deep meaning - where implicatures are). As such they will "interpret" everything that you say literally, instead of going out of their way to misunderstand you.
On the other hand, most people use implicatures all the time, and expect others to be using them all the time. Even when there's none (I call this a "ghost implicature", dunno if there's some academic name). And since written communication already prevents us from seeing some contextual clues that someone's utterance is not to be taken literally, there's a biiiig window for misunderstanding.
[Sorry for nerding out about Linguistics. I can't help it.]
That seems sensible.
Even a hypothetically true artificial general intelligence would still not be a moral agent, thus it cannot be held responsible for its actions; as such, whoever deploys and maintains it should be held responsible. That's doubly true with LLMs as they aren't even intelligent to begin with.
Yeah, as would eliza (at a much lower cost).
Neither Eliza nor LLMs are "insightful", but that doesn't stop them from outputting utterances that a human being would subjectively interpret as such. And the later is considerably better at that.
But the point is that calling them conversations is a long stretch. // You’re just talking to yourself. You’re enjoying the conversation because the LLM is simply saying what you want to hear. // There’s no conversation whatsoever going on there.
Then your point boils down to an "ackshyually", on the same level as "When you play chess against Stockfish you aren't actually «playing chess» as a 2P game, you're just playing against yourself."
This shite doesn't need to be smart to be interesting to use and fulfil some [not all] social needs. Specially in the case of autists (as OP mentioned to be likely in the spectrum); I'm not an autist myself but I lived with them for long enough to know how the cookie crumbles for them, opening your mouth is like saying "please put words here, so you can screech at me afterwards".
People do it all the time regardless of subject. For example, when discussing LLMs:
- If you highlight that they're useful, some assumer will eventually claim that you think that they're smart
- If you highlight that they are not smart, some another assumer will eventually claim that you think that they're useless
- If you say something but "they're dumb but useful", you're bound to get some "I dun unrurrstand, r u against or for LLMs? I'm so confused...", with both above screeching at you.
I've read this text. It's a good piece, but unrelated to what OP is talking about.
The text boils down to "people who believe that LLMs are smart do so for the same reasons as people who believe that mentalists can read minds do." OP is not saying anything remotely close to that; instead, they're saying that LLMs lead to pleasing and insightful conversations in their experience.
My impressions are completely different from yours, but that's likely due
- It's really easy to interpret LLM output as assumptions (i.e. "to vomit certainty"), something that I outright despise.
- I used Gemini a fair bit more than ChatGPT, and Gemini is trained with a belittling tone.
Even then, I know which sort of people you're talking about, and... yeah, I hate a lot of those things too. In fact, one of your bullet points ("it understands and responds...") is what prompted me to leave Twitter and then Reddit.
I couldn't find it to show you, but I remember an episode of The Osbournes where Ozzy put the pet food bowl in the middle of the kitchen, Sharon warned him "don't do this, you'll eventually kick it", then after some time Ozzy kicked the bowl and blamed their pet for moving the bowl to that position.
I don't know if Ozzy has victim mentality, but people with victim mentality do this sort of thing all the time - they never acknowledge that they did something that caused them an issue. And that's bad for both the ones around them and for themselves.
and likewise data as [ˈd̪äːt̪ä] “dah-tah.”
More like [ˈd̪ät̪ä], no long vowel. There's also some disagreements if short /a/ was [ä] or [ɐ], given the symmetry with /e i o u/ as [ɛ ɪ ɔ ʊ]. (I can go deeper on this if anyone wants.)
Another thing that people don't often realise, when they say "you should pronounce it like in Latin!", is that Latin /d t/ were different from English/German /d t/. They were considerably less aspirated, and as your transcription shows they were dental.
That's just details though. Your core point (Latin didn't use a diphthong in this word) is 100% correct.
English covers hundreds of accents and multiple English speaking countries. There isn’t just one pronunciation.
I'm listing the variants that I use.
I'm aware that all three languages have heavy internal variation; for example the Portuguese word could be also pronounced as ['dä.ðuʃ], and a lot of N. Italian speakers don't really do the compensatory lengthening that I do.
a specific kind of “R” (I have no English examples on mind
General American rendering of "butter" as [bʌɾɚ] uses it.
Kind of off-topic but "Brazilian Portuguese" is not an actual variety (language or dialect). It's more like a country-based umbrella term, the underlying varieties (like Baiano, Paulistano, etc.) often don't share features with each other but do it with non-Brazilian varieties.
There's a good example of that in your own transcription of the word "arauto" as /a'ɾawto/. You're probably a Sulista speaker*, like me; the others would raise that vowel to /u/, regardless of country because they share vowel raising. (Unless we're counting Galician into the bag, as it doesn't raise /o/ to /u/ either. But Galician is better dealt separately from Portuguese.)
*PR minus "nortchi", SC minus Florianópolis Desterro, northern RS, Registro-SP.
Desculpe-me pela nerdice não requisitada, ma' é que adoro falar de idiomas.
It's both things, and subjected to wide variation:
| - | Stressed | Unstressed |
|---|---|---|
| Prevocalic | /ði:/ | /ði/, /ðɪ/, /ð/ |
| Preconsonantal | /ði:/, /ðʌ/ | /ðə/ |
Source for those pronunciations, Wiktionary.
To complicate it further some varieties merge /ʌ/ and /ə/, or /ɪ/ and /ə/. And I'm not even taking into account varieties using a different consonant, /t θ d f v/.
The other side of it is believing everything is your fault.
Yeah, both are problematic. And for the same reason - the person does not learn to accurately identify when they're responsible for something and should do something about it, although for different reasons.
Watermelon rinds and citrus peels are perfectly edible and tasty once candied, so don't waste them. If you're into booze, dump the citrus peels into vodka, wait a month, then mix the vodka half-and-half with syrup. (I know that this is technically not a food eating trick, but still - waste not, want not.)
While not a food eating trick, chopsticks are also great when you're deep-frying food - they allow you to firmly hold it for flipping, without piercing it or spooning oil.
I had a supermarket pizza (you know, the one that you buy assembled but raw) and a latte.
[Idea] If you don't want to see huge flags taking space over actual drawings in the Canvas, pick the biggest flag that you can find to deface.
As long as a lot of people are doing that, the ones templating larger flags will be forced to reduce their layouts and give more room for actual drawings.
__________________
[Reasoning] When it comes to country flags, I think that the immense majority of the users can be split into four groups:
- The ones who don't want to see country flags at all.
- The ones who are OK with smaller flags, but don't want to see larger ones.
- The ones who want to see a specific large flag taking a huge chunk of space.
- The ones who want to see the whole canvas burning, like the void.
I'm myself firmly rooted into #1, but this idea is a compromise between #1, #2 and #4.
Typically #3 uses numbers (and/or bots) to seize a huge chunk of the canvas to their flags. Well, let's use numbers against it then. As long as #1, #2 and #4 are trying to wreck the same flag, we win.
___________
[inb4]
>But what about identity flags?
Not a problem. They're typically bands instead of thick squares, and people drawing them are fairly accommodating.
>But what about [insert another thing]
Even if [thing] is a problem, it's probably minor in comparison with huge country flags.
>What should be the template?
None. We don't need one, as long as everyone is working against the same large flag.
Just draw something of your choice over the flag, preferably over its iconic features.
>But I'm not creative enough for that!
No matter how shitty your drawing is, it's probably still way more original than a country flag. So don't feel discouraged.
That said, you can always help someone else with their drawing. Or plop in some text. Or just void.
>Why are you posting this now, you bloody Slowpoke?
I wish that I thought about this before Canvas 2024. But better later than never. (And better early by a year for Canvas 2025.)
____________________
EDIT: addressing on general grounds some whining from group #3 (the ones who want to see a specific large flag taking a huge chunk of the canvas space).
You do realise that this sort of "war against the largest flag" should benefit even you, as long as the biggest flag is not the one you're working with, right? Even for you, this makes the canvas a more even level field. Let us not forget that you love to cover other flags with your own.
Archaeologists discovered the stone tablet at a Tartessian site in southwestern Spain.

I'm sharing this here mostly due to the alphabet. The relevant region (Tartessos) would be roughly what's today the western parts of Andalucia, plus the Algarve.
Here are the news in Spanish, for anyone interested.
The number of letters is specially relevant for me - 32 letters. The writing system is a redundant alphabet, where you use different graphemes for the stops, depending on the next vowel; and it was likely made for a language with five vowels, so you had five letters for /p/, five for /t/, five for /k/. Counting the "bare" vowels this yields 20 letters; /m n s r l/ fit well with that phonology, but what about the other seven?
Context: some days ago, I commented in a topic about Argiope bruennichi that I had a similar spider living on my kumquat tree, later identified to be Argiope argentata. And @quinacridone@lemmy.ml asked for an update, if she laid eggs.
So, here they are. Sadly I couldn't even notice that she laid eggs, let alone photograph the egg sac. But hey, I got little cute spiders~
Here's their mum, Kumoko:
This recipe is great to repurpose lunch leftovers for dinner. It's also relatively mess-free. Loosely based on egg-fried rice.
Amounts listed for two servings, but they're eyeballed so use your judgment.
Ingredients:
- Cooked leftover rice. 200~300g (cooked) is probably good enough. It's fine to use pilaf, just make sure that the rice is cold, a bit dry, and that the grains are easy to separate.
- Two eggs. Cracked into a small bowl and whisked with salt, pepper, and MSG. Or the seasoning of your choice.
- Veg oil. For browning.
- Water. Or broth if you want, it's just a bit.
- [OPTIONAL] Meats. Leftover beef, pork, or chicken work well. Supplement it with ham, firmer sausages, and/or bacon; 1/2 cup should be enough for two. Dice them small.
- [OPTIONAL] Vegs. I'd add at least half raw onion; but feel free to use leftover cooked cabbages, peas, bell peppers, etc. Or even raw ones. Also diced small.
- [OPTIONAL] Chives. Mostly as a finishing touch. Sliced thinly.
Preparation:
- Add a spoonful of veg oil to a wok or similar. Let it heat a bit.
- If using raw meats: add them to the wok, and let them brown on high fire, stirring constantly. Else, skip this step.
- If using raw vegs: add them to the wok, and let them it cook on mid-low fire. Else, skip this step.
- Add the already cooked ingredients (rice, meats, vegs). Medium fire, stirring gentle but constantly; you want to heat them up, not to cook them further. Adjust seasoning if desired.
- Spread the whisked egg over your heated rice mix, while stirring and folding the rice frenetically. You want the egg to coat the rice grains, but they should be still separated when done. If some whisked egg is sticking to the wok and/or the rice is too dry, drip some water/broth and scrap the bottom of the wok; just don't overdo it (you don't want soggy rice). Anyway, when the egg is cooked this step is done, it'll give the rice grains a nice yellow colour and lots of flavour.
- If using chives, add them after your turned off the fire (they get sad if cooked). Enjoy your meal.
I was going to share a picture of the final result, but I may or may not have eaten it before thinking about sharing the recipe. Sorry. :#
I got a weird problem involving both of my cats (Siegfrieda, to the left; Kika, to the right).
Kika is rather particular about having her own litterbox(es), and refuses to use a litterbox shared by another cat. Frieda on the other hand is adept to the "if I fits, I sits, I shits" philosophy, and is totally OK sharing litterboxes.
That creates a problem: no matter if properly and regularly cleaned, the only one using litterboxes here is Frieda. We had, like, five of them at once; and Kika would still rather do her business on the patio.
How do I either teach Kika "it's fine to share a litterbox", or teach Siegfrieda "that's Kika's litterbox, leave it alone"?
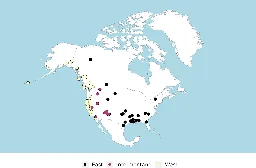
Johanna Nichols, a linguist at the University of California, Berkeley, has used her pioneering work in the field of language history to learn more about language development in North America. She has found that it can be traced back to two language groups that originated in Siberia. Her paper is pub...
Context: my mum got some keikis of this orchid from a neighbour. She managed to grow them into a full plant, it even flowered (as per pic), but she has no idea on which species of orchid it is.
I am not sure if it's a native species here (I'm in the subtropical parts of South America), but it seems to be growing just fine indoors in a Cfb climate.
Disregard the vase saying "phal azul" (blue phal), it used to belong to another orchid; it doesn't seem to be a Phalaenopsis.
If necessary I can provide further pics, but note that it has lost the flowers already.
Any idea?
_____________
EDIT: thanks to @jerry@fedia.io's comment, we could find it - it's a Miltoniopsis. Likely from Colombia or Ecuador, not from my area.
I feel slightly offended. Because it's true.
(Alt text: "Do you feel like the answer depends on whether you're currently in the hole, versus when you refer to the events later after you get out? Assuming you get out.")
Link to the community: !isekai@ani.social
Feel free to join and talk about your favourite series. The rules are rather simple, and they're there to ensure smooth discussion.

I'm sharing this mostly as a historical curiosity; Schleicher was genial, but the book is a century and half old, science marches on, so it isn't exactly good source material. Still an enjoyable read if you like Historical Linguistics, as it was one of the first successful attempts to reconstruct a language based on indirect output from its child languages.
A class of speech sounds that is now present in nearly half of the world’s languages -- labiodentals, produced by positioning the lower lip against the upper teeth, such as in ‘f’ or ‘v’ -- are a relatively recent development, one brought about by post-Neolithic diet-induced changes in the human bit...
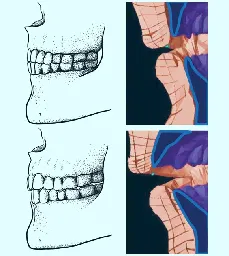
Link for the Science research article. The observation that societies without access to softer food kind of avoided labiodentals is old, from 1985, but the research is recent-ish (2019).
While AI now allows us to erase accents, is this really a good idea? Besides, who doesn’t have an accent?

Même texte en français ici. I'll copypaste the English version here in case of paywall.
Accents are one of the cherished hallmarks of cultural diversity.
Why AI software ‘softening’ accents is problematic
Published 2024/Jan/11\ by Grégory Miras, Professeur des Universités en didactique des langues, Université de Lorraine
“Why isn’t it a beautiful thing?” a puzzled Sharath Keshava Narayana asked of his AI device masking accents.
Produced by his company, Sanas, the recent technology seeks to “soften” the accents of call centre workers in real-time to allegedly shield them from bias and discrimination. It has sparked widespread interest both in the English-speaking and French-speaking world since it was launched in September 2022.
Far from everyone is convinced of the software’s anti-racist credentials, however. Rather, critics contend it plunges us into a contemporary dystopia where technology is used to erase individuals’ differences, identity markers and cultures.
To understand them, we could do worse than reviewing what constitutes an accent in the first place. How can they be suppressed? And in what ways does ironing them out bends far more than sound waves?
How artificial intelligence can silence an accent
“Accents” can be defined, among others, as a set of oral clues (vowels, consonants, intonation, etc.) that contribute to the more or less conscious elaboration of hypotheses on the identity of individuals (e.g. geographically or socially). An accent can be described as regional or foreign according to different narratives.
With start-up technologies typically akin to black boxes, we have little information about the tools deployed by Sanas to standardise our way of speaking. However, we know most methods aim to at least partially transform the structure of the sound wave in order to bring certain acoustic cues closer to a perceptive criteria. The technology tweaks vowels, consonants along with parameters such as rhythm, intonation or accentuation. At the same time, the technology will be looking to safeguard as many vocal cues as possible to allow for the recognition of the original speaker’s voice, such as with voice cloning, a process that can result in deepfake vocal scams. These technologies make it possible to dissociate what is speech-related from what is voice-related.
The automatic and real-time processing of speech poses technological difficulties, the main one being the quality of the sound signal to be processed. Software developers have succeeded in overcoming them by basing themselves on deep learning, neural networks, as well as large data bases of speech audio files, which make it possible to better manage the uncertainties in the signal.
In the case of foreign languages, Sylvain Detey, Lionel Fontan and Thomas Pellegrini identify some of the issues inherent in the development of these technologies, including that of which standard to use for comparison, or the role that speech audio files can have in determining them.
The myth of the neutral accent
But accent identification is not limited to acoustics alone. Donald L. Rubin has shown that listeners can recreate the impression of a perceived accent simply by associating faces of supposedly different origins with speech. In fact, absent these other cues, speakers are not so good at recognising accents that they do not regularly hear or that they might stereotypically picture, such as German, which many associate with “aggressive” consonants.
The wishful desire to iron out accents to combat prejudice raises the question of what a “neutral” accent is. Rosina Lippi-Green points out that the ideology of the standard language - the idea that there is a way of expressing oneself that is not marked - holds sway over much of society but has no basis in fact. Vijay Ramjattan further links recent collossal efforts to develop accent “reduction” and “suppression” tools with the neoliberal model, under which people are assigned skills and attributes on which they depend. Recent capitalism perceives language as a skill, and therefore the “wrong accent” is said to lead to reduced opportunities.
Intelligibility thus becomes a pretext for blaming individuals for their lack of skills in tasks requiring oral communication according to Janin Roessel. Rather than forcing individuals with “an accent to reduce it”, researchers such as Munro and Derwing have shown that it is possible to train individuals to adapt their aural abilities to phonological variation. What’s more, it’s not up to individuals to change, but for public policies to better protect those who are discriminated against on the basis of their accent - accentism.
Delete or keep, the chicken or the egg?
In the field of sociology, Wayne Brekhus calls on us to pay specific attention to the invisible, weighing up what isn’t marked as much as what is, the “lack of accent” as well as its reverse. This leads us to reconsider the power relations that exist between individuals and the way in which we homogenise the marked: the one who has (according to others) an accent.
So we are led to Catherine Pascal’s question of how emerging technologies can hone our roles as “citizens” rather than “machines”. To “remove an accent” is to value a dominant type of “accent” while neglecting the fact that other co-factors will participate in the perception of this accent as well as the emergence of discrimination. “Removing the accent” does not remove discrimination. On the contrary, the accent gives voice to identity, thus participating in the phenomena of humanisation, group membership and even empathy: the accent is a channel for otherness.
If technologies such AI and deep learning offers us untapped possibilities, they can also lead to a dystopia where dehumanisation overshadows priorities such as the common good or diversity, as spelt out in the UNESCO Universal Declaration on Cultural Diversity. Rather than hiding them, it seems necessary to make recruiters aware of how accents can contribute to customer satisfaction and for politicians to take up this issue.
Research projects such as PROSOPHON at the University of Lorraine (France), which bring together researchers in applied linguistics and work psychology, are aimed at making recruiters more aware of their responsibilities in terms of biais awareness, but also at empowering job applicants “with an accent”. By asking the question “Why isn’t this a beautiful thing?”, companies like SANAS remind us why technologies based on internalized oppressions don’t make people happy at work.

{kind=link}
Small bit of info: Charles III still speaks RP, but the prince William (heir to the throne) already shifted to SSBE. Geoffrey Lindsey has a rather good video on that.
Links to the community:
- /c/linguistics@mander.xyz
- !linguistics@mander.xyz
The community is open for everyone regardless of previous knowledge on the field. Feel free to ask or share stuff about languages and dialects, how they work (grammar, phonology, etc.), where they're from, how people use them, or more general stuff about human linguistic communication.
And the rules are fairly simple. They boil down to 1) stay on-topic, 2) source it when reasonable, 3) avoid pseudoscience.
Have fun!
This is a rather long study, from the Oxford Studies in Ancient Documents. Its general content should be clear by the title, and it focuses on three "chunks" of the former Roman empire: Maghreb and Iberia, Gallia and Germania, and the British Isles.
I've recreated a Linguistics community here in mander.xyz. As the sidebar says, it's for everyone, regardless of previous knowledge over the field, so even if you're a layperson feel free to drop by.
Here's the link: !linguistics@mander.xyz
In case that you're in a Kbin/Mbin instance and the above doesn't work, try /m/linguistics@mander.xyz instead.
Reading stories regularly strengthens social-cognitive skills—such as empathy—in both children and adults. And this, in turn, ensures that we can empathize with characters more effectively and more quickly when we are reading. This is the subject of linguist Lynn Eekhof's Ph.D., which she will recei...

Further info: the linguist in question is Lynn S. Eekhof, and she has quite a few publications about the topic, worth IMO reading.
 Lvxferre @mander.xyz
Lvxferre @mander.xyz The catarrhine who invented a perpetual motion machine, by dreaming at night and devouring its own dreams through the day.